Web Scraping là gì? 4 điều bạn cần biết trước khi bắt đầu sử dụng

Trong thời đại dữ liệu số bùng nổ, nhu cầu thu thập và xử lý thông tin từ Internet ngày càng trở nên cấp thiết. Đây chính là lúc Web Scraping phát huy vai trò như một giải pháp mạnh mẽ, thay thế cho các phương pháp thu thập dữ liệu thủ công vốn tốn thời gian và nguồn lực.
Vậy Web Scraping là gì? Nó hoạt động như thế nào và mang lại giá trị gì cho cá nhân hoặc doanh nghiệp? Hãy cùng Hidemium khám phá những điều quan trọng bạn cần nắm rõ trước khi bắt đầu sử dụng công nghệ này.
1. Web Scraping là gì?
Web Scraping là kỹ thuật tự động thu thập thông tin từ các trang web thông qua các phần mềm hoặc đoạn mã được gọi là bots. Những bots này sẽ truy cập vào mã nguồn HTML của trang web, trích xuất dữ liệu cần thiết và lưu lại dưới dạng file bảng tính, cơ sở dữ liệu, hoặc tích hợp thông qua API, phục vụ các mục đích như: nghiên cứu thị trường, cập nhật dữ liệu sản phẩm, phân tích đối thủ cạnh tranh,…
Công cụ thực hiện quá trình này được gọi là Web Scraper. Web Scraper được thiết kế để quét và phân tích cấu trúc của website, xác định các phần tử chứa thông tin quan trọng (ví dụ: giá, tên sản phẩm, nội dung bài viết) và tự động thu thập chúng theo cấu hình định sẵn.

>>> Tìm hiểu thêm: WebRTC là gì? Các trang web có thu thập dấu vân tay WebRTC không?
2. Web Scraping được sử dụng để làm gì?
Web Scraping là kỹ thuật thu thập dữ liệu từ các trang web một cách tự động, hiện đang được ứng dụng rộng rãi trong nhiều lĩnh vực khác nhau. Dưới đây là những mục đích phổ biến nhất của Web Scraping:
Thu thập dữ liệu thị trường: Giúp doanh nghiệp nhanh chóng truy xuất thông tin về giá cả, phản hồi khách hàng và xu hướng tiêu dùng từ các trang thương mại điện tử, hỗ trợ hiệu quả cho phân tích cạnh tranh và nghiên cứu thị trường.
Nghiên cứu và phân tích thông tin xã hội: Công cụ Web Scraping có thể lấy dữ liệu từ báo điện tử, diễn đàn, blog hoặc website chính phủ để phục vụ việc đánh giá xu hướng, dư luận xã hội và hành vi người dùng.
Tự động cập nhật tin tức: Hệ thống có thể liên tục thu thập các bản tin mới nhất từ các nguồn uy tín, giúp người dùng cập nhật thông tin nhanh chóng mà không cần theo dõi thủ công từng trang.
Thu thập dữ liệu sản phẩm và dịch vụ: Trong lĩnh vực thương mại điện tử, việc sử dụng Web Scraper để lấy dữ liệu từ đối thủ cạnh tranh giúp doanh nghiệp nắm bắt thị trường và điều chỉnh chiến lược sản phẩm hiệu quả.
Tối ưu hóa chiến dịch quảng cáo – tiếp thị: Các thông tin về hành vi khách hàng và đối thủ cạnh tranh thu được qua Web Scraping sẽ là nền tảng quan trọng để doanh nghiệp nâng cao hiệu quả marketing kỹ thuật số.
Theo dõi và so sánh giá trực tuyến: Công cụ này giúp người dùng và doanh nghiệp giám sát giá cả sản phẩm hoặc dịch vụ từ nhiều nguồn khác nhau, từ đó dễ dàng tìm được mức giá tốt nhất.
Tổng hợp dữ liệu đa nguồn: Web Scraper hỗ trợ gom dữ liệu từ nhiều website, tạo ra kho dữ liệu tổng hợp phục vụ cho phân tích chuyên sâu và ra quyết định kinh doanh.
Tự động hóa nội dung: Dữ liệu thu được có thể được xử lý để tạo nội dung tự động cho website, blog hoặc các ứng dụng, giúp tiết kiệm thời gian sản xuất nội dung thủ công.
>>> Tìm hiểu thêm: Cách nhận biết antidetect có chức năng Webrtc giả tốt
3. Ứng dụng Web Scraping trong các lĩnh vực nổi bật
Theo thống kê từ LinkedIn tại Mỹ, Web Scraping đã và đang được ứng dụng rộng rãi trong hơn 54 lĩnh vực khác nhau. Dưới đây là 10 ngành tiêu biểu có tỷ lệ sử dụng Web Scraping cao nhất:
Phần mềm máy tính – 22%
Công nghệ thông tin & dịch vụ kỹ thuật số – 21%
Tài chính – ngân hàng – bảo hiểm – 16%
(bao gồm: dịch vụ tài chính 12%, bảo hiểm 2%, ngân hàng 2%)Internet và nền tảng trực tuyến – 11%
Quảng cáo & tiếp thị số – 5%
An ninh mạng & bảo mật thông tin – 3%
Tư vấn quản lý – 2%
Truyền thông và xuất bản kỹ thuật số – 2%
Điều này cho thấy, Web Scraping không chỉ hữu ích trong lĩnh vực công nghệ, mà còn là công cụ quan trọng trong việc thu thập dữ liệu thị trường, giám sát đối thủ cạnh tranh, theo dõi xu hướng và tự động hóa phân tích người dùng trong nhiều ngành công nghiệp khác nhau.
>>> Tìm hiểu thêm: Pixel Tracking là gì? 3 loại Pixel Tracking phổ biến nhất
4. Các loại Web Scraper phổ biến nhất hiện nay
Web Scraper là công cụ tự động thu thập dữ liệu từ các trang web. Dựa trên tiêu chí kỹ thuật và trải nghiệm người dùng, Web Scraper có thể được phân loại như sau:
4.1. Theo cách xây dựng: Tự phát triển (Self-built) và có sẵn (Pre-built)
Self-built (tự xây dựng): Được lập trình riêng bằng các ngôn ngữ phổ biến như Python, Java hoặc Node.js. Loại này yêu cầu người dùng có kỹ năng lập trình và hiểu biết sâu về hệ thống web.
Pre-built (có sẵn): Là các thư viện và công cụ hỗ trợ như Scrapy, BeautifulSoup (Python) hoặc Puppeteer (JavaScript). Phù hợp với người dùng muốn triển khai nhanh và không cần xây dựng từ đầu.
4.2. Theo hình thức triển khai: Tiện ích trình duyệt vs Phần mềm độc lập
Browser Extension: Là tiện ích mở rộng tích hợp vào trình duyệt, cho phép lấy dữ liệu trực tiếp từ trang web đang truy cập.
Software (phần mềm): Là các ứng dụng độc lập, cài đặt trên máy tính, có khả năng hoạt động tách biệt với trình duyệt, thường mạnh mẽ và tùy biến cao.
4.3. Theo giao diện người dùng: Có giao diện (With UI) vs Không giao diện (Without UI)
With UI: Có giao diện đồ họa trực quan, dễ sử dụng cho người không chuyên kỹ thuật.
Without UI: Vận hành qua dòng lệnh (CLI), yêu cầu kỹ năng lập trình và phù hợp với nhà phát triển chuyên sâu.
4.4. Theo nơi lưu trữ và xử lý dữ liệu: Cloud-based vs Local
Cloud-based: Các công cụ chạy trên nền tảng đám mây, hỗ trợ xử lý và lưu trữ dữ liệu linh hoạt, mở rộng theo nhu cầu và không phụ thuộc vào thiết bị người dùng.
Local: Cài đặt và chạy trực tiếp trên máy tính cá nhân. Người dùng cần tự cấu hình, bảo trì và chịu trách nhiệm về hiệu suất hệ thống.
>>> Tìm hiểu thêm: User Agent là gì? Cách thay đổi UA trên 4 trình duyệt phổ biến hiện nay
5. Web Scraping hoạt động như thế nào?
Web Scraping là quá trình tự động thu thập dữ liệu từ các website, được ứng dụng rộng rãi trong nghiên cứu thị trường, theo dõi giá cả, phân tích nội dung và nhiều mục đích khác. Để bắt đầu, bạn cần nhập URL của website mục tiêu vào công cụ Scraper. Sau đó, công cụ sẽ tải toàn bộ mã HTML của trang – bao gồm cả JavaScript và CSS nếu cần thiết.
Người dùng có thể lựa chọn các loại dữ liệu cụ thể muốn trích xuất như: giá sản phẩm, kích thước, tiêu đề bài viết hoặc nội dung chi tiết. Scraper sau đó sẽ duyệt qua các trang liên quan để thu thập thông tin tương ứng. Nếu website có cấu trúc tĩnh, dữ liệu có thể được cấu hình tự động. Tuy nhiên, với phần lớn các trang động, người dùng cần thiết lập thủ công do cấu trúc HTML khác nhau.
Dữ liệu sau khi thu thập sẽ được xuất ra dưới các định dạng phổ biến như CSV, Excel hoặc JSON – định dạng lý tưởng để tích hợp với các hệ thống API.
Mặc dù Web Scraping là công cụ mạnh mẽ cho việc xử lý và khai thác dữ liệu quy mô lớn, nhưng nó không phải lúc nào cũng dễ dàng triển khai, đặc biệt là với những ai cần chạy nhiều tài khoản hoặc thực hiện tự động hóa nâng cao. Nhiều website hiện nay đã triển khai các biện pháp bảo mật như chặn IP, phát hiện thiết bị lạ, khiến việc thu thập dữ liệu bị gián đoạn.
Đây là lý do tại sao trình duyệt chống phát hiện Hidemium trở thành lựa chọn lý tưởng. Hidemium cho phép bạn quản lý nhiều hồ sơ trình duyệt, kết hợp sử dụng proxy để thay đổi địa chỉ IP và dấu vết thiết bị, giúp bạn bypass các rào cản bảo mật của website một cách hiệu quả và an toàn.
Tóm lại, Web Scraping là giải pháp tuyệt vời để thu thập thông tin trong thời đại dữ liệu số, nhưng đi kèm với đó là những lưu ý quan trọng về mặt pháp lý và đạo đức. Hãy luôn đảm bảo rằng việc thu thập dữ liệu được thực hiện một cách hợp pháp. Nếu bạn cần hỗ trợ về công cụ hoặc cách triển khai, đừng ngần ngại liên hệ với Hidemium để được tư vấn chi tiết.
>>> Bài viết liên quan:
Bài viết liên quan

Giải Pháp Thay Thế Multilogin Tốt Nhất Cho Đội Nhóm Năm 2026Giải pháp thay thế Multilogin tốt nhất năm 2026 là Hidemium dành cho các đội nhóm cần một cách thực tế để quản lý nhiều hồ sơ trình duyệt, tổ chức quy trình làm việc nhóm, gán proxy, tách biệt không gian làm việc trực tuyến và mở rộng quy mô vận hành tài khoản mà không tạo thêm sự phức tạp không cần thiết. Đây cũng là giải pháp thay thế[…]

Bạn đang thắc mắc cách tính thu nhập Tiktok như thế nào và làm sao để tối ưu hóa nguồn thu nhập từ nền tảng video ngắn phổ biến nhất hiện nay? Hiểu rõ cơ chế trả thưởng của Tiktok và áp dụng các chiến lược kiếm tiền thông minh là chìa khóa để biến đam mê sáng tạo nội dung thành nguồn thu nhập ổn định.Bài viết này Hidemium sẽ cung cấp cho bạn cái nhìn toàn diện về cách Tiktok tính thu nhập, phân[…]
.png)
Dù bạn là quản trị viên mạng xã hội, affiliate marketer hay người cần vận hành nhiều tài khoản cùng lúc, trình duyệt antidetect là giải pháp tối ưu giúp mỗi hồ sơ trực tuyến hoạt động như một người dùng độc lập. Để tối ưu hiệu quả công việc và đảm bảo an toàn, việc cập nhật thông tin về các nền tảng chống phát hiện mới là điều cần thiết.Trong bài viết này, chúng tôi sẽ đánh giá chi[…]

DNS Viettel là giải pháp đơn giản nhưng hiệu quả giúp người dùng vượt qua các rào cản truy cập mạng như bị chặn Facebook, tải video YouTube chậm, hoặc kết nối Internet không ổn định. Vậy hiện tại, Viettel đang cung cấp những địa chỉ DNS nào? Làm thế nào để thay đổi DNS nhằm cải thiện tốc độ truy cập mạng? Hãy cùng Hidemium khám phá chi tiết qua bài viết sau.1. Danh sách địa chỉ DNS Viettel phổ[…]

Mọi người có biết ngành thương mại điện tử Việt Nam đang lớn mạnh thế nào không? Thương mại điện tử tại nước ta đang tăng trưởng rất nhanh, dự kiến doanh thu sẽ đạt mức 87.36 tỷ USD vào năm 2031. Đã bao giờ các tài khoản bán hàng của bạn bị khóa hàng loạt mà không rõ lý do chưa?. Việc giữ kết nối ổn định và quản lý hồ sơ người dùng là một bài toán khó cho mọi đội ngũ. Bởi vì khi làm việc trên các[…]
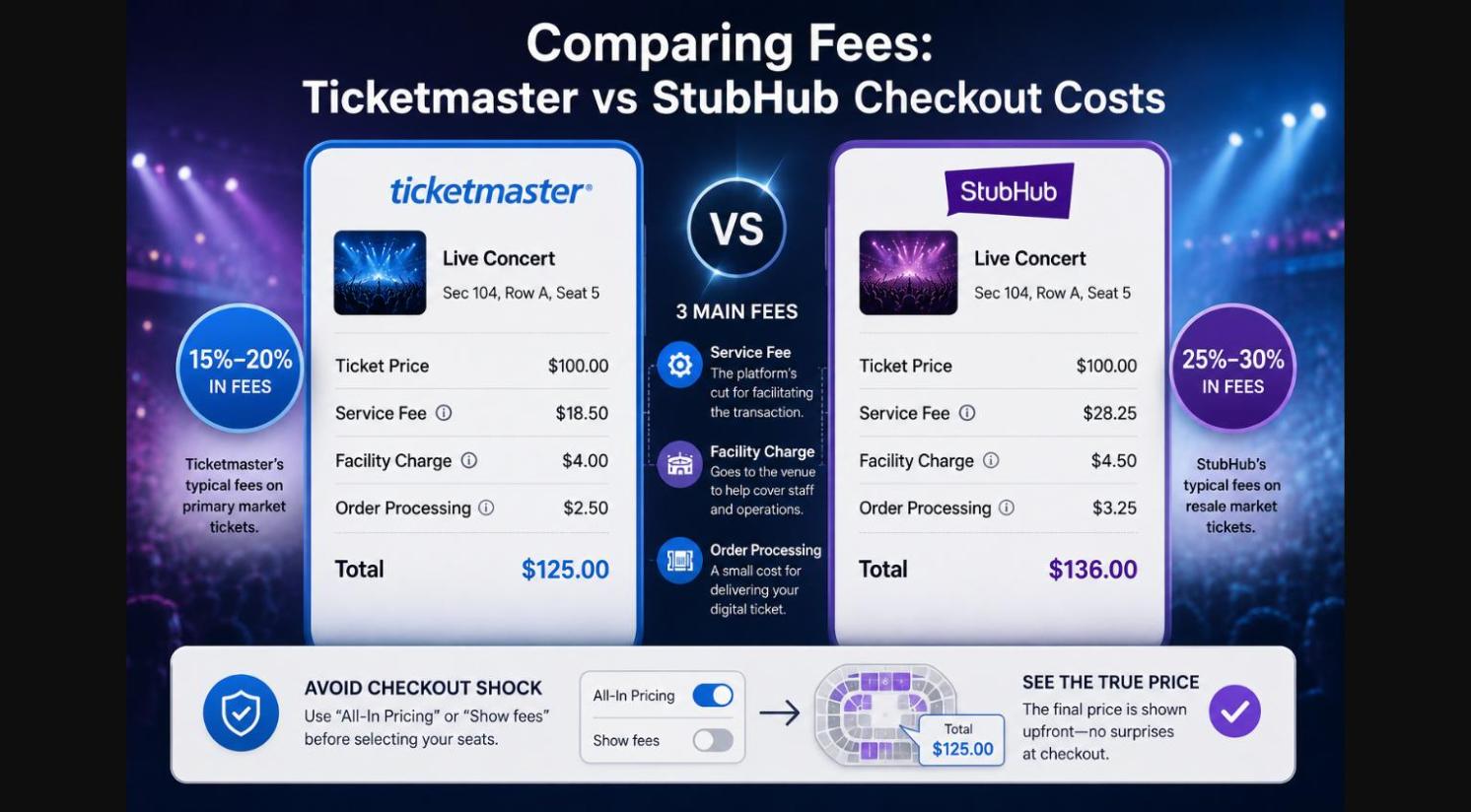
StubHub và TicketmasterHiểu về thị trường vé sơ cấp và thứ cấp: Ticketmaster và StubHubBạn xếp hàng trong hàng đợi ảo suốt một tiếng đồng hồ để mua vé concert đình đám, chỉ để nhận về thông báo "Đã hết vé". Điều bực bội hơn nữa là những ghế đó lại xuất hiện trên trang khác vài phút sau với giá gấp ba. Với người hâm mộ bình thường, cuộc chiến StubHub vs Ticketmaster đôi khi cảm giác như một trò[…]
